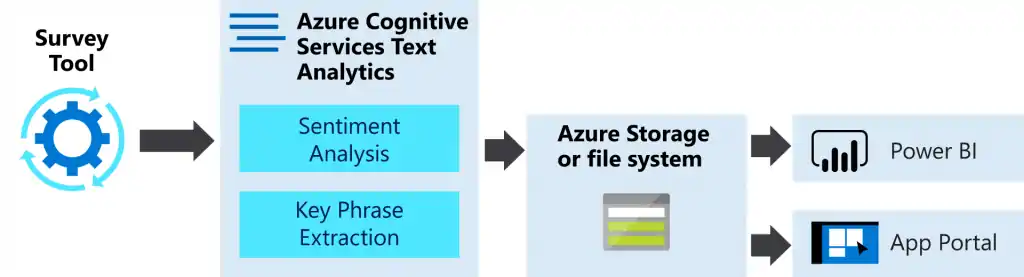
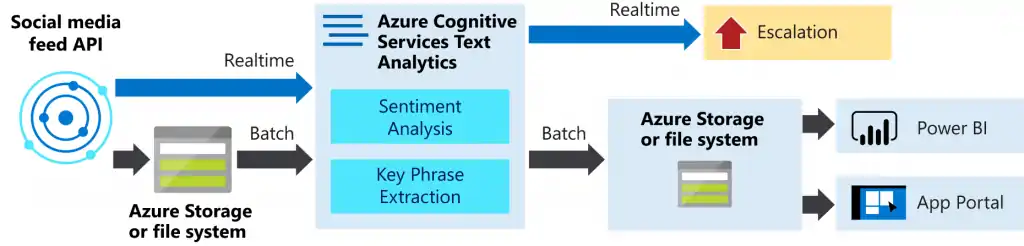
It is estimated that around 80% of all information is unstructured, with the text being one of the most common types of unstructured data. Because of the messy nature of the text, analyzing, understanding, organizing, and sorting through text data is hard and time-consuming so most companies fail to extract value from that.
This is where text analytics with machine learning steps in. By using this, companies can structure business information such as email, legal documents, web pages, chat conversations, and social media messages in a fast and cost-effective way. This allows companies to save time when analyzing text data, help inform business decisions and automate business processes.